有嚴重者,甚至能侵害版權。那么這么龐大的信息,搜索引擎蜘蛛是怎么做到的呢?做網站seo的朋友一定要熟知這方面的知識,只有找對了問題的所在,才能突破收錄排名局限!請先看一下圖片吧。 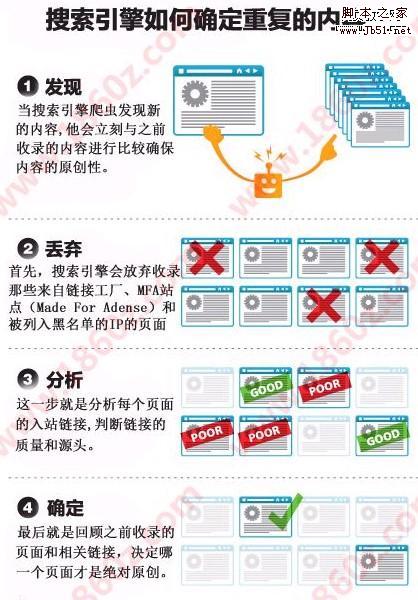
相信大家都能看懂圖片的含義吧,比較生動一點,下面簡單的給大家表述一下這四個步驟。
1.發現內容:當搜索引擎爬蟲發現新內容的時候,他就會理科與之前收錄的內容進行比較,確保網站的內容原創性!這一步很關鍵。如果是偽原創內容的話,請一定保證80%以上的不同!
2.信息丟棄:首先搜索引擎會放棄收錄那些來自連接工廠,mfa站點(made for adense)和被列入黑名單的ip頁面。
3.鏈接分析:這一步就是分析每個頁面的入站鏈接,判斷鏈接的質量和源頭。這一步也是做導入鏈接的關鍵部分,在有限的時間內,做好高質量的鏈接,保證數量!
4.最后確定:最后就是回顧之前收錄的頁面和相關鏈接,決定哪一個頁面才是絕對原創。并把原創內容放到排名前面。
總結,這里雖然設計的有的原創,有的偽原創,也有的可能是直接轉載。百度蜘蛛和Google機器人默認的排名是最開始的創始地點。最原始的排名越靠前!
