ASR(Automatic Speech Recognition) 自動語音識別,是一種使用計算機來識別人通過電話或麥克說話產生的語音信號的語音技術。作為專門的研究領域,ASR又是一門交叉學科,它與聲學、語音學、語言學、數字信號處理理論、信息論、計算機科學等眾多學科緊密相連。
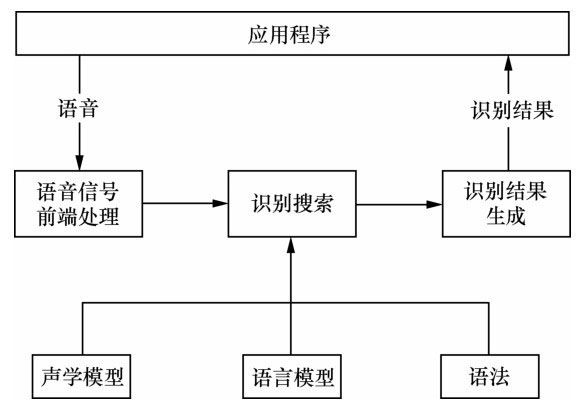
在ASR中用到的最主要的技術是隱馬爾可夫模型(Hidden Markov Model,HMM)。這種技術通過判斷每個相鄰小區的語音信號最可能是哪一個音素來識別單詞,因為詞匯表里的單詞其實就是音素的組合。通過一種叫作Viterbi(一種動態規劃算法,一般用于序列的譯碼)的搜索過程來決定最有可能是哪一個因素序列。搜索局限于詞匯表的單詞所對應的音素序列。ASR引擎的工作過程如圖:
①前端語音處理:完成端點(話音的起始點和結束點)檢測、降噪等。
②識別:根據聲學模型、語言模型、語法進行識別。聲學模型是語音識別系統中最關鍵的部分,它的作用就是前面提到的確定音素序列。語言模型是指語言中的一些規則或語法結構,是表現字或詞上下文之間的統計模型。語言模型可以預測在句子中某個位置最可能出現的單詞。語法對所有可能識別的語言進行描述,簡單地說,語法告訴識別器應該聽什么。語法可以用有向圖來描述,圖中的節點可以是一個單詞或一個句子,如果識別成功,識別的結果將是圖的一條路徑。
③產生識別結果:識別結果按照一定的文本結構返回。
ASR分為兩種:一種是獨立于人的識別,即不管是誰,只要他說的話是一樣的,識別結果都是相同的,它主要應用于人機交互,使用語言作為輸入的優勢是顯而易見的,方便快捷;另一種是特定人的識別,又叫聲紋校驗,主要用來進行身份驗證。在本文中討論的ASR指的是第一種。
由于語音信號的多樣性和復雜性,目前的語音識別系統只能在一定的限制條件下獲得滿意的性能,或者說只能應用于某些特定的場合。語音識別系統的性能大致取決于以下4類因素:識別詞匯表的大小和語音的復雜性;語音信號的質量;單個說話人還是多說話人;硬件平臺。
語音識別技術的應用包括語音撥號、IVR語音導航、室內設備控制、語音文檔檢索、簡單的聽寫數據錄入等。語音識別技術與其他自然語言處理技術如機器翻譯及語音合成技術相結合,可以構建出更加復雜的應用,例如語音到語音的翻譯。語音識別技術所涉及的領域包括:信號處理、模式識別、概率論和信息論、發聲機理和聽覺機理、人工智能等等。特別是在電話機器人中的IVR起作重要的作作